Setting up a data-playground with docker-compose and Faker
In the past few days I played around with Airflow to get familiar with its DAG syntax. Instead of scrambling around to find the right dataset to be imported in a MySQL instance I’ve decided to set-up a development environment from scratch that allowed me to quickly change the structure and type of data as I pleased. I’ve found this approach quite handy for three reasons:
- No time wasted on finding the right dataset in the interwebs.
- Very easy to extend and adapt to any scenario.
- Completely free: running locally, there’s no need to provision and manage a small database instance.
Beyond being a very easy way to set up a data playground, the following approach can also
be adapted in scenarios where sensitive data is involved and using a replica of
the actual db is not an option.
You can find the repo on github to follow along.
Overview
The structure of the tool is fairly straightforward: any sub folder inside local-dev/
contains a Dockerfile that will spawn a database (a MySQL instance in this case) and
populate each table through dedicated Python scripts.
.
├── docker-compose.cli.yaml
├── docker-compose.yaml
├── local-dev
│ ├── mysql-seeding
│ │ ├── Dockerfile
│ │ ├── requirements.txt
│ │ ├── seed_mysql.sh
│ │ ├── seed_transactions.py
│ │ ├── seed_users.py
│ │ └── utils.py
│ └── tests
│ ├── Dockerfile
│ ├── entrypoint.sh
│ ├── requirements.txt
│ └── tests.py
└── README.md
This process relies on a very simple docker-compose file to orchestrate the setup
process, with the only restriction of waiting for the db to be up before seeding the mock
entries. In order to wait for the db it will be enough to specify depends_on on the
seeding service and wait
for the db connection to be ready in the seeding scripts.
version: '3'
services:
mysql:
image: mariadb:10.5
container_name: mysql_db
ports:
- "3306:3306"
expose:
- "3306"
environment:
MYSQL_ROOT_PASSWORD: "root"
MYSQL_DATABASE: "database"
mysql_seeding:
container_name: mysql_seeding
build: ./local-dev/mysql-seeding
depends_on:
- mysql
The repo offers a docker-compose.cli.yaml file with an additional test container that will
take care of checking that all the tables have been set up properly. We can check
everything works locally by pointing docker-compose to the alternate file with
docker-compose -f docker-compose.cli.yaml up --build.
Database setup & Faker
For this example, I have set up a pretty easy setup, relying on a database containing a users and a transactions table structured as shown below.
users table:
| id | name | state | birthday | notes | is_adult | |
|---|---|---|---|---|---|---|
| 1 | Benjamin Rodriguez | ywong@yahoo.com | IT | 1985-03-26 22:37:54 | You sit clear team family trial. | 0 |
| 2 | Tracy Morales | douglas92@yahoo.com | IT | 1997-03-04 13:05:10 | News television real development. | 1 |
| 3 | Julie Thomas MD | fgarza@hotmail.com | EN | 1987-01-06 22:46:02 | Then end note. | 1 |
| 4 | Vernon Wilson | stephanie83@hotmail.com | EN | 1974-01-11 01:05:32 | Her me child prepare. | 1 |
| 5 | Adam Duran | jameschristian@yahoo.com | IT | 1977-04-28 15:26:31 | Animal hundred become right citizen. | 0 |
transactions table:
| id | order_id | user_id | ts | amount | currency_code | item | is_premium |
|---|---|---|---|---|---|---|---|
| 1 | 4048 | 315 | 1993-09-06 01:53:12 | 8580.4900 | MGA | green apple | 1 |
| 2 | 5268 | 40 | 2019-11-27 15:10:26 | 618.3500 | XCD | yellow banana | 1 |
| 3 | 7650 | 249 | 1994-02-27 01:47:14 | 1489.7300 | HKD | samrt fox | 1 |
| 4 | 7460 | 332 | 2010-03-12 11:57:00 | 1519.2600 | SEK | cool watermelon | 1 |
| 5 | 3170 | 171 | 1981-05-30 21:15:37 | 4565.9800 | AFN | strange pear | 1 |
As mentioned above, Faker has been used to populate these tables. The library has a number
of built-in data providers to replicate pretty much any entry (emails, addresses, zip codes, etc.).
As an example seed_transactions.py
will create 2.000 transactions for the same user ids created by seed_users.py.
def insert_transactions(self):
uids = self.get_users()
transactions = []
for _ in range(2000):
transaction = {
"order_id": faker.pyint(min_value=1, max_value=9999, step=1),
"user_id": faker.random.choice(uids),
"ts": faker.date_time(),
"amount": faker.pydecimal(
left_digits=4, right_digits=2, min_value=1
),
"currency_code": faker.currency_code(),
"item": faker.random.choice(constants['products']),
"is_premium": faker.boolean(chance_of_getting_true=50)
}
transactions.append(transaction)
self.connection.execute(self.Transactions.insert(), transactions)
Testing everything works fine
In order to test that everything works flawlessly, a second docker-compose file is included
in the repo. This file has the same content of the original one except for spawning an
extra container that will run a python script (based on pytest) to check that the tables have
been created correctly. Pytest fixtures
can be used to set up a db connection before launching the actual tests:
import pytest
@pytest.fixture
def db_conn():
from sqlalchemy import (
create_engine,
engine
)
from sqlalchemy.ext.automap import automap_base
from sqlalchemy.exc import InterfaceError
config = {
"drivername": "mysql+mysqlconnector",
"username": "root",
"password": "root",
"host": "mysql",
"port": "3306",
"database": "database",
}
Base = automap_base()
try:
engine = create_engine(engine.url.URL(**config))
except InterfaceError:
print("Something went wrong while connecting to MySQL db")
Base.prepare(engine, reflect=True)
yield engine
print("Disposing engine")
engine.dispose()
def test_user_table_exists(db_conn):
assert db_conn.has_table("users") == True
def test_tx_table_exists(db_conn):
assert db_conn.has_table("transactions") == True
Setting up Github Actions
In order to make sure that no change will break the environment, the above mentioned
docker-compose file can be integrated as a CI step as a Github Action. In a nutshell,
the action will take care of building the images, setting up the containers and running the
tests.py file.
The workflow is pretty basic and it will be triggered both both on new pull requests
and every time a commit will be pushed to master.
name: run-tests
on:
push:
branches: master
pull_request:
branches:
- master
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Build containers
run: docker-compose -f docker-compose.cli.yaml up -d
- name: Start db
run: docker start mysql_db
- name: Seed db mock entries
run: docker start mysql_seeding
- name: Run tests
run: docker start mysql_seeding_test --attach
The --attach flag will send the output of the test script to stdout, allowing to be
inspected further.
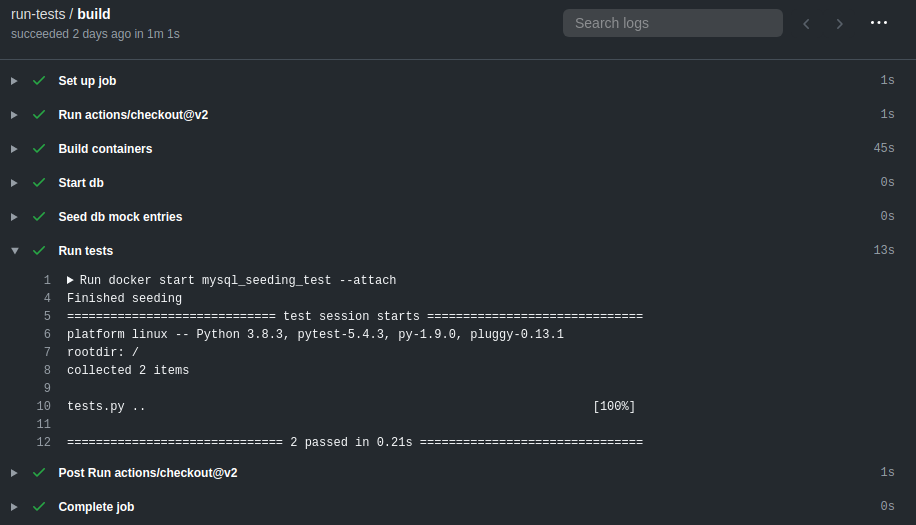
edit: For some reason, using the --attach flag when running tests gets Github Actions to hang
until the step will timeout (~ 6hrs).
Conclusions
A few points have been discussed in this post:
- How to structure a back end development environment avoiding to provision extra databases.
- How to use
docker-composeto set up different db instances and seed them with mock data. - Set up Github Actions to integrate tests in the CI pipeline to check all the tables needed have been set up correctly.